Modelos híbridos
Introducción
La regresión lineal sobresale en la extrapolación de tendencias, pero no puede aprender interacciones. XGBoost sobresale en el aprendizaje de interacciones, pero no puede extrapolar tendencias. En este post, aprenderemos cómo crear predictores “híbridos” que combinan algoritmos de aprendizaje complementarios y permiten que las fortalezas de uno compensen las debilidades del otro.
Componentes y residuos
Para que podamos diseñar híbridos efectivos, necesitamos comprender mejor cómo se construyen las serie temporales. Hemos analizado tres patrones de dependencia: tendencias, estacionalidad y ciclos. Muchas series temporales se pueden describir con precisión mediante un modelo aditivo de solo estos tres componentes más algunos errores esencialmente impredecibles y completamente aleatorios.
series = tendencia + estacionalidad + ciclos + error
Cada uno de los términos de este modelo se podría denominar componente de la serie temporal.
Los residuos de un modelo son las diferencias entre el objetivo en el que se entrenó el modelo y las predicciones que hace el modelo; en otras palabras, la diferencia entre la curva real y la curva entrenada. Si dibujamos los residuos contra una feature, obtendremos la parte “sobrante” del objetivo o lo que el modelo no pudo aprender sobre el objetivo a partir de esa feature.
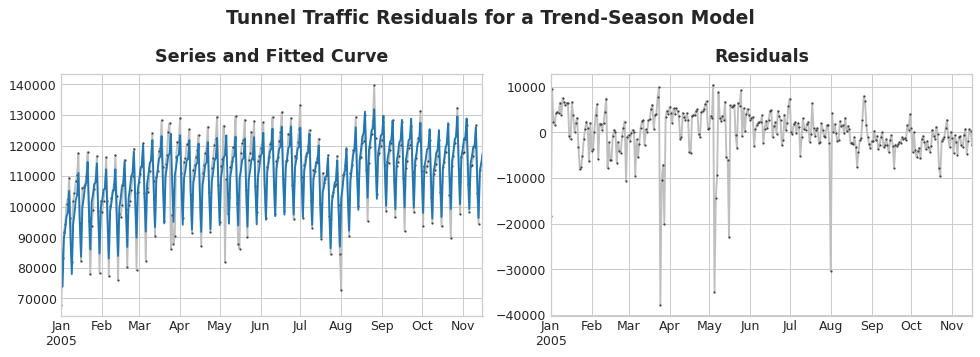
La diferencia entre la serie objetivo y las predicciones (azul) proporciona la serie de residuos. En la izquierda de la figura se muestra una porción de la serie de Tráfico del Túnel y la curva de tendencia-estacionalidad. Al restar la curva entrenada quedan los residuos, a la derecha. Los residuos contienen todo lo que el modelo de tendencia-estacionalidad no aprendió del Tráfico del Túnel.
Podríamos imaginar aprender los componentes de una serie temporal como un proceso iterativo: primero se aprende la tendencia y se resta de la serie, luego se aprende la estacionalidad a partir de los residuos sin tendencia y se resta la estacionalidad, después se aprenden los ciclos y se restan los ciclos y, finalmente, solo queda el errore impredecible.
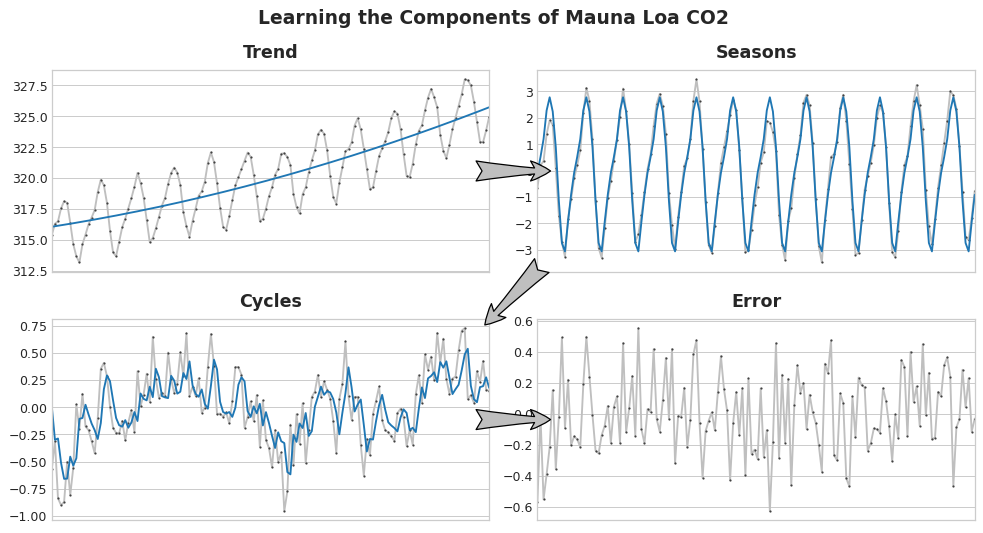
En la figura se muestra el aprendizaje de componentes del datasets de CO2 de Mauna Loa paso por paso. Al restar la curva entrenada (azul) de su serie se obtiene la serie del siguiente paso.
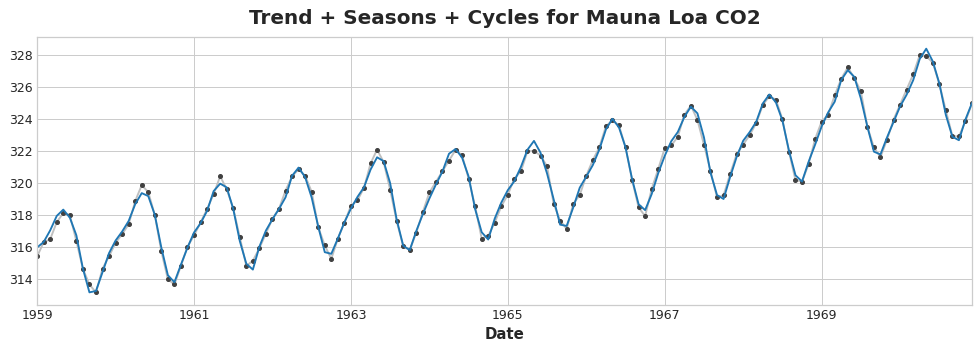
Al sumar todos los componentes juntos que aprendimos obtenemos el modelo completo. Esto es esencialmente lo que haría la regresión lineal si la entrenamos en un conjunto completo de features que modelan tendencias, estacionalidad y ciclos.
Predicción híbrida con residuos
En anteriores posts, usamos un único algoritmo (regresión lineal) para aprender todos los componentes a la vez. Pero también es posible usar un algoritmo para unos componentes y otro algoritmo para el resto. De esta forma, siempre podemos elegir el mejor algoritmo para cada componente. Para hacer esto, usaremos un algoritmo para entrenar la serie original y después un segundo algoritmo para entrenar las series residuales.
Este proceso sería algo así:
# 1. Entrena y predice con el primer modelo
model_1.fit(X_train_1, y_train)
y_pred_1 = model_1.predict(X_train)
# 2. Entrena y predice con el segundo modelo en los residuos
model_2.fit(X_train_2, y_train - y_pred_1)
y_pred_2 = model_2.predict(X_train_2)
# 3. Agrega para obtener las predicciones totales
y_pred = y_pred_1 + y_pred_2
Por lo general, querremos usar conjuntos de features diferentes (X_train_1 y X_train_2) dependiendo de lo que queramos que aprenda cada modelo. Si usamos el primer modelo para aprender tendencias, normalmente no necesitaríamos una feature de tendencia para el segundo modelo, por ejemplo.
Aunque es posible usar más de dos modelos, en la práctica no parece ser especialmetne útil. De hecho, la estrategia más común para construir híbridos es la que acabamos de describir: un algoritmo de aprendizaje sencillo (generalmente lineal) seguido por uno complejo, un predictor no lineal como GBDT o una red neuronal profunda, considerándose generalmente el modelo sencillo como un “ayudante” para el poderoso algortimo que le sigue.
Diseñando híbridos
Existen muchas formas de combinar modelos de machine learning además de la forma que hemos descrito anteriormente. Sin embargo, la combinación exitosa de modelos requiere que profundicemos un poco más en cómo operan estos algoritmos.
Generalmente, existen dos maneras en las que un algoritmo de regresión hace sus predicciones: transformando las features o transformando el objetivo. Los algoritmos de transformación de features aprenden alguna función matemática que toma las features como entrada y después las combina y transforma para producir una salida que iguale los valores objetivos del conjunto de entrenamiento. La regresión lineal y las redes neuronales son de este tipo.
Los algoritmos de transformación de objetivo usan las features para agrupar los valores objetivo del conjunto de entrenamiento y realizan predicciones promediando los valores en un grupo; un conjunto de features solo indica qué grupo promediar. Los árboles de decisión y nearest neighbors son de este tipo.
Lo importante es que los transformadores de features normalmente puede extrapolar los valores objetivo más allá del conjunto de entrenamiento dadas las apropiadas features como entrada. Por el contrario, las predicciones de los transformadores de objetivo siempre estarán limitados al rango del conjunto de entrenamiento. Si el time dummy siguiera contando pasos de tiempo, la regresión lineal continuaría dibujando la línea de tendencia. Dado el mismo time dummy, un árbol de decisión predecirá la tendencia indicada por el último paso de los datos de entrenamiento en el futuro por siempre. Los árboles de decisión no pueden extrapolar tendencias. Los bosques aleatorios y los árboles de decisión gradient boosted (como XGBoost) son conjuntos de árboles de decisión, por lo que tampoco pueden extrapolar tendencias.
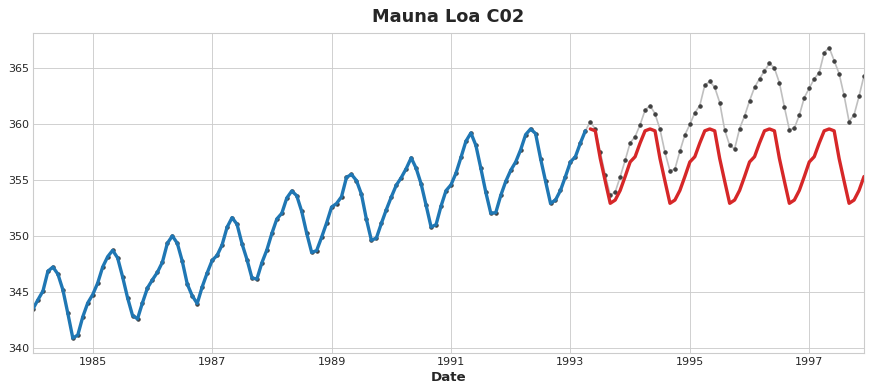
En la figura anterior, se puede ver (en rojo) que un árbol de decisión fallará al extrapolar una tendencia más allá de los datos de entrenamiento.
Esta diferencia entre ambos tipos de algoritmos es lo que motiva el diseño de híbridos: usaremos regresión lineal para extrapolar la tendencia, trasformaremos el objetivo para eliminar la tendencia y aplicaremos XGBoost a los residuos sin tendencia. Para hibridar una red neuronal (un transformador de features), podríamos incluir las predicciones de otro modelo como una feature, que la red neuronal incluiría como parte de sus propias predicciones. El método de entrenamiento de residuos es realmente el mismo método que usa el algoritmo de gradient boosting, por lo que los llamaremos híbridos boosted; el método de usar prediccioens como features es conocido como stacking, por lo que los llamaremos híbridos stacked.
Algunos ganadores híbridos de competiciones Kaggle
- STL boosted with exponential smoothing - Walmart Recruiting - Store Sales Forecasting
- ARIMA and exponential smoothing boosted with GBDT - Rossmann Store Sales
- An ensemble of stacked and boosted hybrids - Web Traffic Time Series Forecasting
- Exponential smoothing stacked with LSTM neural net - M4 (non-Kaggle)
Ejemplo - Venta Minorista EEUU
El dataset de Venta Minorista de EEUU contiene datos de venta mensuales de varias industrias minoristas desde 1992 a 2019, recopiladas por la Oficina del Censo de EEUU. Nuestro objetivo será predecir las ventas en los años 2016 a 2019 dadas las ventas de los años anteriores. Además de crear un híbrido regresión lineal + XGBOost, también veremos cómo configurar una serie temporal para usarla con XGBoost.
from warnings import simplefilter
import matplotlib.pyplot as plt
import pandas as pd
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
from statsmodels.tsa.deterministic import CalendarFourier, DeterministicProcess
from xgboost import XGBRegressorsimplefilter("ignore")
# Set Matplotlib defaults
plt.style.use("seaborn-whitegrid")
plt.rc(
"figure",
autolayout=True,
figsize=(11, 4),
titlesize=18,
titleweight='bold',
)
plt.rc(
"axes",
labelweight="bold",
labelsize="large",
titleweight="bold",
titlesize=16,
titlepad=10,
)
plot_params = dict(
color="0.75",
style=".-",
markeredgecolor="0.25",
markerfacecolor="0.25",
)industries = ["BuildingMaterials", "FoodAndBeverage"]
retail = pd.read_csv(
"../data/us-retail-sales.csv",
usecols=['Month'] + industries,
parse_dates=['Month'],
index_col='Month',
).to_period('D').reindex(columns=industries)
retail = pd.concat({'Sales': retail}, names=[None, 'Industries'], axis=1)
retail.head()| Sales | ||
|---|---|---|
| Industries | BuildingMaterials | FoodAndBeverage |
| Month | ||
| 1992-01-01 | 8964 | 29589 |
| 1992-02-01 | 9023 | 28570 |
| 1992-03-01 | 10608 | 29682 |
| 1992-04-01 | 11630 | 30228 |
| 1992-05-01 | 12327 | 31677 |
Primero usaremos un modelo de regresión lineal para entrenar la tendencia en cada serie. A efectos de demostración, usaremos una tendencia cuadrática (orden 2). Aunque el entrenamiento no es perfecto, será suficiente para nuestras necesidades.
y = retail.copy()
# Crea features de tendencia
dp = DeterministicProcess(
index=y.index, # fechas de los datos de en entrenamiento
constant=True, # intercept
order=2, # tendencia cuadrática
drop=True, # elimina términos para evitar colinearidad
)
X = dp.in_sample() # features de los datos de entrenamiento# Prueba en los años 2016-2019. Será más facil para nosotros después si
# dividimos el índice de fechas en lugar de directamente el dataframe.
idx_train, idx_test = train_test_split(
y.index, test_size=12 * 4, shuffle=False,
)
X_train, X_test = X.loc[idx_train, :], X.loc[idx_test, :]
y_train, y_test = y.loc[idx_train], y.loc[idx_test]# Entrena el modelo de tendencia
model = LinearRegression(fit_intercept=False)
model.fit(X_train, y_train)LinearRegression(fit_intercept=False)
# Hace predicciones
y_fit = pd.DataFrame(
model.predict(X_train),
index=y_train.index,
columns=y_train.columns,
)
y_pred = pd.DataFrame(
model.predict(X_test),
index=y_test.index,
columns=y_test.columns,
)# Plot
axs = y_train.plot(color='0.25', subplots=True, sharex=True)
axs = y_test.plot(color='0.25', subplots=True, sharex=True, ax=axs)
axs = y_fit.plot(color='C0', subplots=True, sharex=True, ax=axs)
axs = y_pred.plot(color='C3', subplots=True, sharex=True, ax=axs)
for ax in axs: ax.legend([])
_ = plt.suptitle("Tendencias")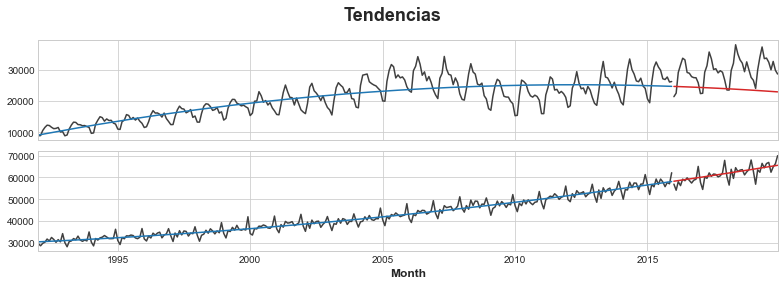
Mientras que el algoritmo de regresión lineal es capaz de regresión multi-salida, el algoritmo XGBoost no. Para predecir múltiples series a la vez con XGBoost, convertiremos dichas series de formato ancho, con una serie temporal por columna, a formato largo, con series indexadas por categorías a lo largo de las filas.
# El método `stack` convierte etiquetas de columna a etiquetas de fila, pivotando de formato ancho a largo
X = retail.stack()
display(X.head())
y = X.pop('Sales')| Sales | ||
|---|---|---|
| Month | Industries | |
| 1992-01-01 | BuildingMaterials | 8964 |
| FoodAndBeverage | 29589 | |
| 1992-02-01 | BuildingMaterials | 9023 |
| FoodAndBeverage | 28570 | |
| 1992-03-01 | BuildingMaterials | 10608 |
Para que XGBoost pueda aprender a distinguir dos series temporales, convertiremos las etiquetas de fila de Industries en una feature categórica con un etiqueta codificada. También crearemos una feature para la estacionalidad anual extrayendo los números de mes del índice de tiempo.
# Convierte etiquetas de fila en columnas de feature categóricas con codificación de etiquetas
X = X.reset_index('Industries')
# Codificación de etiqueta para la feature 'Industries'
for colname in X.select_dtypes(["object", "category"]):
X[colname], _ = X[colname].factorize()
# Codifica la etiqueta para estacionalidad anual
X["Month"] = X.index.month # 1, 2, ..., 12
# Crea divisiones
X_train, X_test = X.loc[idx_train, :], X.loc[idx_test, :]
y_train, y_test = y.loc[idx_train], y.loc[idx_test]Ahora convertiremos las predicciones de tendencias realizadas anteriormente a formato largo y las restaremos de la serie original. Esto nos dará las series sin tendencias (residuos) que puede aprender XGBoost.
# Pivota de ancho a largo (stack) y convierte de DataFrame a Series (squeeze)
y_fit = y_fit.stack().squeeze() # tendencia del conjunto de entrenamiento
y_pred = y_pred.stack().squeeze() # tendencia del conjunto de prueba
# Crea residuos (la colección de series sin tendencia) del conjunto de entrenamiento
y_resid = y_train - y_fit
# Entrena XGBoost en los residuos
xgb = XGBRegressor()
xgb.fit(X_train, y_resid)
# Y añade los residuos predichos en las tendencias predichas
y_fit_boosted = xgb.predict(X_train) + y_fit
y_pred_boosted = xgb.predict(X_test) + y_predEl ajuste parece bastante bueno. Aunque podemos ver cómo la tendencia aprendida por XGBoost es tan buena como la aprendida por la regresión lineal, en particular XGBoost no fue capaz de compensar la tendencia pobremente ajustada de la serie BuildingMaterials.
axs = y_train.unstack(['Industries']).plot(
color='0.25', figsize=(11, 5), subplots=True, sharex=True,
title=['BuildingMaterials', 'FoodAndBeverage'],
)
axs = y_test.unstack(['Industries']).plot(
color='0.25', subplots=True, sharex=True, ax=axs,
)
axs = y_fit_boosted.unstack(['Industries']).plot(
color='C0', subplots=True, sharex=True, ax=axs,
)
axs = y_pred_boosted.unstack(['Industries']).plot(
color='C3', subplots=True, sharex=True, ax=axs,
)
for ax in axs: ax.legend([])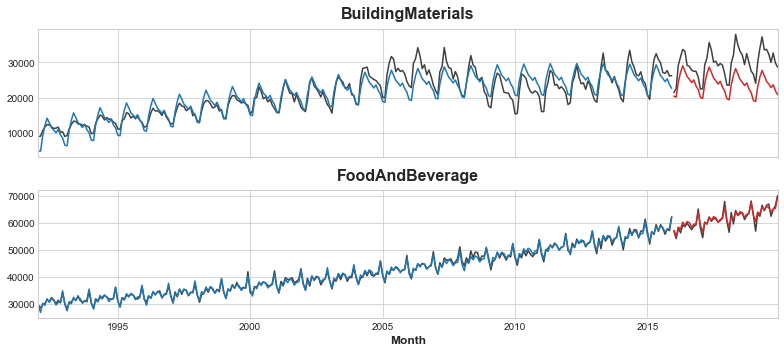
Ejercicio
Vamos a realizar un ejercicio para ampliar lo que acabamos de ver.
import matplotlib.pyplot as plt
import pandas as pd
from sklearn.linear_model import LinearRegression
from sklearn.preprocessing import LabelEncoder
from statsmodels.tsa.deterministic import DeterministicProcess
from xgboost import XGBRegressor
from helpers.style import *store_sales = pd.read_csv(
"../data/store_sales/train.csv",
usecols=["store_nbr", "family", "date", "sales", "onpromotion"],
dtype={
"store_nbr": "category",
"family": "category",
"sales": "float32",
},
parse_dates=["date"],
infer_datetime_format=True,
)
store_sales["date"] = store_sales.date.dt.to_period("D")
store_sales = store_sales.set_index(["store_nbr", "family", "date"]).sort_index()
store_sales.head()| sales | onpromotion | |||
|---|---|---|---|---|
| store_nbr | family | date | ||
| 1 | AUTOMOTIVE | 2013-01-01 | 0.0 | 0 |
| 2013-01-02 | 2.0 | 0 | ||
| 2013-01-03 | 3.0 | 0 | ||
| 2013-01-04 | 3.0 | 0 | ||
| 2013-01-05 | 5.0 | 0 |
family_sales = (
store_sales
.groupby(['family', 'date'])
.mean()
.unstack('family')
.loc['2017']
)
family_sales.head()| sales | ... | onpromotion | |||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| family | AUTOMOTIVE | BABY CARE | BEAUTY | BEVERAGES | BOOKS | BREAD/BAKERY | CELEBRATION | CLEANING | DAIRY | DELI | ... | MAGAZINES | MEATS | PERSONAL CARE | PET SUPPLIES | PLAYERS AND ELECTRONICS | POULTRY | PREPARED FOODS | PRODUCE | SCHOOL AND OFFICE SUPPLIES | SEAFOOD |
| date | |||||||||||||||||||||
| 2017-01-01 | 0.092593 | 0.037037 | 0.055556 | 74.222221 | 0.000000 | 9.084685 | 0.129630 | 7.500000 | 11.518518 | 3.629167 | ... | 0.0 | 0.018519 | 0.111111 | 0.018519 | 0.0 | 0.000000 | 0.037037 | 0.129630 | 0.0 | 0.000000 |
| 2017-01-02 | 11.481482 | 0.259259 | 11.648149 | 6208.055664 | 0.481481 | 844.836304 | 14.203704 | 2233.648193 | 1545.000000 | 539.114807 | ... | 0.0 | 0.462963 | 10.592593 | 0.537037 | 0.0 | 0.259259 | 1.166667 | 5.629630 | 0.0 | 0.407407 |
| 2017-01-03 | 8.296296 | 0.296296 | 7.185185 | 4507.814941 | 0.814815 | 665.124084 | 10.629630 | 1711.907349 | 1204.203735 | 404.300079 | ... | 0.0 | 0.481481 | 9.722222 | 0.444444 | 0.0 | 0.388889 | 1.351852 | 56.296296 | 0.0 | 0.407407 |
| 2017-01-04 | 6.833333 | 0.333333 | 6.888889 | 3911.833252 | 0.759259 | 594.160583 | 11.185185 | 1508.036987 | 1107.796265 | 309.397675 | ... | 0.0 | 0.370370 | 12.037037 | 0.444444 | 0.0 | 0.296296 | 5.444444 | 101.277778 | 0.0 | 0.333333 |
| 2017-01-05 | 6.333333 | 0.351852 | 5.925926 | 3258.796387 | 0.407407 | 495.511597 | 12.444445 | 1241.833374 | 829.277771 | 260.776489 | ... | 0.0 | 8.981481 | 5.666667 | 0.000000 | 0.0 | 0.296296 | 0.907407 | 5.018519 | 0.0 | 0.444444 |
5 rows × 66 columns
Vamos a crear un híbrido boosted para el dataset de Venta de Almacén implementando una nueva clase Python. Añadiremos un método fit y predict para darle un interfaz similar a scikit-learn.
class BoostedHybrid:
def __init__(self, model_1, model_2):
self.model_1 = model_1
self.model_2 = model_2
self.y_columns = None # almacena los nombre de columna para el método fit
def fit(self, X_1, X_2, y):
# Entrena model_1
self.model_1.fit(X_1, y)
# Hace predicciones
y_fit = pd.DataFrame(
self.model_1.predict(X_1),
index=X_1.index, columns=y.columns,
)
# Calcula residuos
y_resid = y - y_fit
y_resid = y_resid.stack().squeeze() # ancho a largo
# Entrena model_2 en los residuos
self.model_2.fit(X_2, y_resid)
# Guarda los nombres de las columnas para el método predict
self.y_columns = y.columns
def predict(self, X_1, X_2):
# Predice con model_1
y_pred = pd.DataFrame(
self.model_1.predict(X_1),
index=X_1.index, columns=self.y_columns,
)
y_pred = y_pred.stack().squeeze() # ancho a largo
# Añade predicciones de model_2 a predicciones de model_1
y_pred += self.model_2.predict(X_2)
return y_pred.unstack()Ya estamos listos para usar la nueva clase BoostedHybrid y crear un modelo para los datos de Venta de Almacén.
# Series objetivo
y = family_sales.loc[:, 'sales']
# X_1: Features para Regresión Lineal
dp = DeterministicProcess(index=y.index, order=1)
X_1 = dp.in_sample()
# X_2: Features para XGBoost
X_2 = family_sales.drop('sales', axis=1).stack() # onpromotion feature
# Codificado de etiquetas para 'family'
le = LabelEncoder() # de sklearn.preprocessing
X_2 = X_2.reset_index('family')
X_2['family'] = le.fit_transform(X_2['family'])
# Codificado de etiquetas para estacionalidad
X_2["day"] = X_2.index.day # los valores son días del mesVamos a crear el modelo híbrido inicializando la clase BoostedHybrid con instancias de LinearRegression() y XGBRegressor().
model = BoostedHybrid(LinearRegression(), XGBRegressor())
# Entrena y predice
model.fit(X_1, X_2, y)
y_pred = model.predict(X_1, X_2)
y_pred = y_pred.clip(0.0)Dependiendo de nuestro problema, podríamos usar otra combinación diferente a regresión lineal + XGBoost. Por ejemplo, otros algoritmos podrían ser:
# Model 1 (tendencia)
from sklearn.linear_model import ElasticNet, Lasso, Ridge
# Model 2
from sklearn.ensemble import ExtraTreesRegressor, RandomForestRegressor
from sklearn.neighbors import KNeighborsRegressor
from sklearn.neural_network import MLPRegressor
# Podemos intentar diferentes combinaciones
model = BoostedHybrid(
model_1=Ridge(),
model_2=KNeighborsRegressor(),
)y_train, y_valid = y[:"2017-07-01"], y["2017-07-02":]
X1_train, X1_valid = X_1[: "2017-07-01"], X_1["2017-07-02" :]
X2_train, X2_valid = X_2.loc[:"2017-07-01"], X_2.loc["2017-07-02":]
# Algunos de los algortimos anteriores lo hacen mejor con determinados tipos
# de preprocesamient en la features (como standardization), pero es es solo
# una demo.
model.fit(X1_train, X2_train, y_train)
y_fit = model.predict(X1_train, X2_train).clip(0.0)
y_pred = model.predict(X1_valid, X2_valid).clip(0.0)
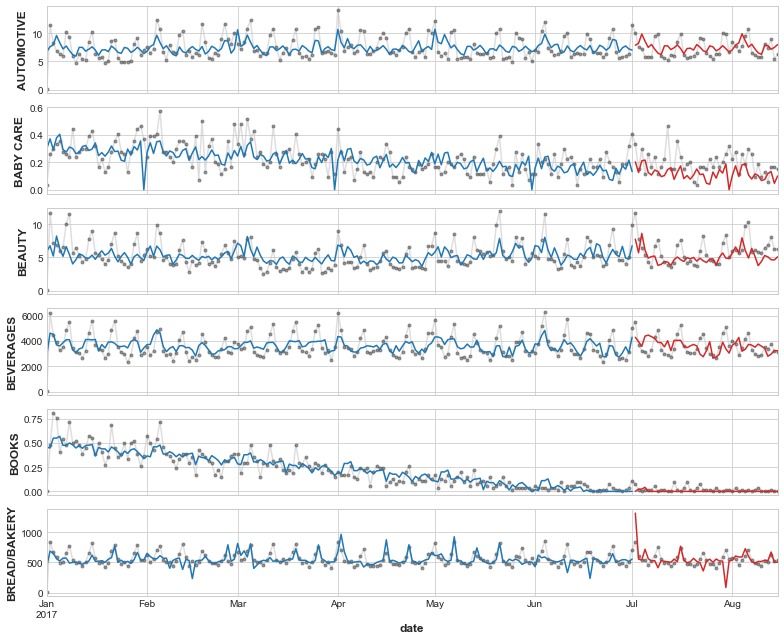
families = y.columns[0:6]
axs = y.loc(axis=1)[families].plot(
subplots=True, sharex=True, figsize=(11, 9), **plot_params, alpha=0.5,
)
_ = y_fit.loc(axis=1)[families].plot(subplots=True, sharex=True, color='C0', ax=axs)
_ = y_pred.loc(axis=1)[families].plot(subplots=True, sharex=True, color='C3', ax=axs)
for ax, family in zip(axs, families):
ax.legend([])
ax.set_ylabel(family)