Introducción a las series temporales
Este es el primero de una serie de posts donde hablaremos de las series temporales. Las series temporales son conjuntos de datos que se recopilan a lo largo del tiempo en intervalos regulares, como días, semanas, meses o años. Estos datos se utilizan para analizar cómo cambian las cosas con el tiempo y para hacer predicciones sobre el futuro. Se busca pronosticar valores futuros basados en valores pasados.
Las series temporales son útiles en una amplia variedad de aplicaciones, incluyendo finanzas, marketing, ventas, ingeniería, climatología, medicina, etc. Algunos ejemplos de casos de uso para series temporales son:
-
Predicción de ventas: Las series temporales se pueden utilizar para predecir las ventas futuras de un producto o servicio. Esto es útil para planificar la producción, la logística y las ventas.
-
Análisis del mercado financiero: Las series temporales se utilizan en el análisis del mercado financiero para predecir el precio de las acciones, las tasas de interés, las fluctuaciones del mercado y otros indicadores financieros.
-
Pronóstico del clima: Las series temporales se utilizan en la climatología para predecir el tiempo y el clima. Esto es útil para la agricultura, la aviación, el turismo y otros sectores que dependen del clima.
-
Análisis de la demanda de energía: Las series temporales se utilizan para predecir la demanda futura de energía y para planificar la producción de energía y la distribución.
-
Monitoreo de la salud: Las series temporales se utilizan para monitorear la salud de los pacientes y para predecir posibles complicaciones. Esto es útil para la prevención y el tratamiento de enfermedades.
En el campo del aprendizaje automático, las series temporales también son útiles para desarrollar modelos que puedan predecir el futuro en función de datos históricos. Los modelos de series temporales se utilizan, por ejemplo, en aplicaciones como la detección de fraudes, la detección de anomalías, la predicción de precios de acciones y la predicción de la demanda de productos.
Las series temporales tienen varios componentes que contribuyen a su patrón y comportamiento a lo largo del tiempo. Estos componentes se pueden dividir en cuatro categorías principales:
-
Tendencia: La tendencia se refiere a la dirección general en la que se mueven los datos a lo largo del tiempo. Describe el comportamiento de las series temporales a largo plazo. La tendencia puede ser ascendente, descendente o plana. Es común que las series temporales tengan una tendencia, ya que muchas variables cambian de manera gradual a lo largo del tiempo. Usando la tendencia podemos realizar declaraciones del tipo “Cada vez nacen menos niños en España”.
-
Estacionalidad: La estacionalidad se refiere a patrones regulares que se repiten a lo largo del tiempo. Estos patrones pueden ser diarios, semanales, mensuales, anuales o cualquier otro intervalo de tiempo. La estacionalidad puede ser causada por factores como el clima, las vacaciones, las tendencias de compra, etc. Usando la estacionalidad podemos realizar declaraciones del tipo “el nivel de partículas de NO$_2$ es bajo en verano y muy alto en invierno”. Este patrón se repite anualmente, independientemente de que la cantidad real sea la misma cada verano.
-
Ciclo: El ciclo se refiere a patrones repetitivos a largo plazo que no están relacionados con la estacionalidad. El ciclo puede estar influenciado por factores económicos, políticos o sociales y puede tener una duración variable. Un ejemplo podría ser la variación anual en la venta de juguetes. La venta de juguetes generalmente aumenta durante las temporadas navideñas, pero también puede haber aumentos o disminuciones en función de otros factores, como la economía, las tendencias de la industria, etc.
-
Ruido: El ruido se refiere a las fluctuaciones aleatorias en los datos que no se pueden atribuir a ninguna tendencia, estacionalidad o ciclo. El ruido puede ser causado por factores como la variabilidad en la medición de los datos o eventos imprevistos. Un ejemplo podría ser la fluctuación diaria en la temperatura ambiental. Incluso si hay una tendencia a largo plazo en el aumento de la temperatura debido al cambio climático, hay fluctuaciones diarias en la temperatura que no tienen una explicación clara. Al modelar una serie temporal, es importante tener en cuenta el componente de ruido y considerar cómo afecta a los pronósticos. Además, también puede ser útil analizar y modelar el componente de ruido por separado para comprender mejor las variaciones aleatorias en la serie temporal.
La identificación y separación de estos componentes es importante en el análisis de series temporales. Al comprender los componentes subyacentes de los datos, es posible realizar pronósticos más precisos y tomar mejores decisiones basadas en los datos. Los modelos de series temporales utilizan técnicas como el análisis de regresión y el análisis espectral para separar y modelar estos componentes.
Regresión lineal con series temporales
Veamos una serie temporal con un ejemplo.
import pandas as pd
df = pd.read_csv(
"../data/ventas_libros.csv",
index_col="Date",
parse_dates=["Date"],
), axis=1)
df.head()| Ventas | |
|---|---|
| Date | |
| 2000-04-01 | 139 |
| 2000-04-02 | 128 |
| 2000-04-03 | 172 |
| 2000-04-04 | 139 |
| 2000-04-05 | 191 |
Esta serie registra el número de ventas de libros en una tienda durante 30 días. Por simplicidad, tiene una única columna de observaciones, Ventas con un índice de tiempo Date.
Usaremos el algoritmo de regresión lineal para construir modelos predictivos. Estos algoritmos aprenden cómo hacer una suma ponderada a partir de sus variables de entrada. Para dos variables tendríamos:
objetivo = peso_1 * feature_1 + peso_2 + feature_2 + bias
Esta ecuación toma la forma de una línea recta en un espacio de dos dimensiones o de un hiperplano en un espacio de dimensiones superiores.
Durante el entrenamiento, el algoritmo de regresión aprende los valores para los parámetros peso_1, peso_2 y bias que mejor se ajustan al objetivo. A este algoritmo se le suele llamar mínimos cuadrados ordinarios ya que busca minimizar la suma de los errores cuadrados entre las predicciones del modelo y los valores observados. Los pesos también se denominan coeficientes de regresión y representan la pendiente. Al bias también se le llama intercept, porque representa la intersección de la línea o el hiperplano.
Features de paso de tiempo
Existen dos tipo de features únicas y distintivas de las series temporales: las variables de pasos de tiempo (time-step) y las variables de lag.
Las features de pasos de tiempo son variables que se pueden derivar directamente del índice de tiempo y se refieren a los intervalos regulares entre las observaciones en la serie temporal. Por ejemplo, si estamos trabajando con una serie temporal que mide la temperatura diaria, cada time step podría ser un día. La feature de pasos de tiempo más básica es la dummy (time dummy), que cuenta el número de pasos de tiempo en las series desde el principio al final.
import numpy as np
df["Time"] = np.arange(len(df.index))
df.head()| Ventas | Time | |
|---|---|---|
| Date | ||
| 2000-04-01 | 139 | 0 |
| 2000-04-02 | 128 | 1 |
| 2000-04-03 | 172 | 2 |
| 2000-04-04 | 139 | 3 |
| 2000-04-05 | 191 | 4 |
La regresión lineal con la time dummy produce el siguiente modelo:
objetivo = peso * time + bias
import matplotlib.pyplot as plt
import seaborn as sns
fig, ax = plt.subplots(figsize=(11, 4))
ax.plot("Time", "Ventas", data=df, color="0.75")
ax = sns.regplot(x="Time", y="Ventas", data=df, ci=None,
scatter_kws=dict(color="0.25"))
ax.set_title("Ventas de libros");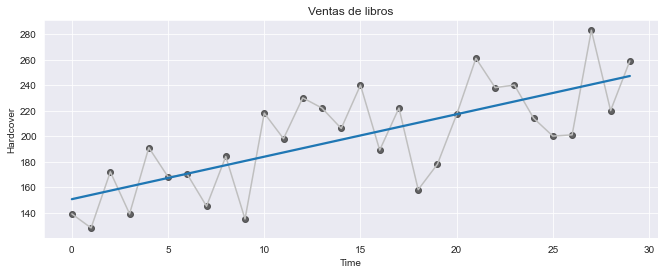
Las features de pasos de tiempo nos permiten modelar la dependencia del tiempo. La dependencia del tiempo se refiere al hecho de que los valores de una serie temporal están correlacionados en el tiempo, es decir, los valores futuros dependen de los valores pasados. Una serie es dependiente del tiempo si sus valores se pueden predecir desde el momento en que ocurrieron. En las series de nuestro ejemplo, podemos predecir que las ventas al final de mes son generalmente más altas que las ventas al principio del mes.
Features de lag
Una variable lag se refiere a un valor previo o pasado de la serie temporal que se utiliza como predictor para predecir los valores futuros. En otras palabras, una variable lag es un retraso de la serie temporal en el tiempo, donde el número de períodos de retraso se denomina como “lag”.
Para hacer una variable lag deslizamos las observaciones de las series del objetivo para que parezcan haber ocurrido más tarde en el tiempo. Aquí hemos creado una variable lag de 1-paso, aunque también es posible desplazar varios pasos.
df["Lag_1"] = df["Ventas"].shift(1)
df = df.reindex(columns=["Ventas", "Lag_1"])
df.head()| Ventas | Lag_1 | |
|---|---|---|
| Date | ||
| 2000-04-01 | 139 | NaN |
| 2000-04-02 | 128 | 139.0 |
| 2000-04-03 | 172 | 128.0 |
| 2000-04-04 | 139 | 172.0 |
| 2000-04-05 | 191 | 139.0 |
La regresión lineal con la variable lag produce el siguiente modelo:
objetivo = peso * lag + bias
Entonces, las variables de lag nos permiten dibujar gráficas donde cada observación en una serie se dibuja contra la observación anterior.
fig, ax = plt.subplots()
ax = sns.regplot(x="Lag_1", y="Ventas", data=df, ci=None,
scatter_kws=dict(color="0.25"))
ax.set_aspect("equal")
ax.set_title("Gráfico lag de Ventas");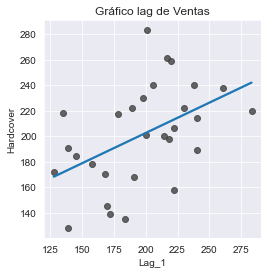
Podemos ver en el gráfico de lag que las ventas de un día (Ventas) están correlacionadas con las ventas del día anterior (Lag_1). Cuando vemos una relación como ésta sabemos que una variable de lag será útil.
De forma más genérica, las features de lag nos permiten modelar la dependencia en serie o serial. La dependencia serial se refiere a la relación entre los valores consecutivos en una serie temporal. En otras palabras, la dependencia serial implica que el valor de una observación en un momento dado está relacionado con el valor de la observación anterior, y así sucesivamente a lo largo de la serie temporal. Una serie temporal tiene dependencia serial cuando una observación se puede predecir a partir de las observaciones previas. En nuestro ejemplo, podemos predecir que ventas altas en un día, generalmente significan ventas altas en el siguiente día.
La adaptación de los algoritmos de machine learning a los problemas de series temporales se trata en gran medida con la ingeniería de features del índice de tiempo y los lags. Aunque estamos usando regresión lineal, estas variables serán útiles independientemente del algoritmo que seleccionemos para nuestras predicciones.
Ejemplo - Tráfico túnel
El tráfico de túnel es una serie temporal que describe el número de vehículos que viajan a través del Túnel de Baregg en Suiza cada día desde noviembre 2002 a noviembre 2005. En este ejemplo, practicaremos aplicando regresión lineal a variables de pasos de tiempo y variables lag.
tunnel = pd.read_csv(
"../data/tunnel.csv",
index_col="Day",
parse_dates=["Day"])
tunnel.to_period()
tunnel.head()| NumVehicles | |
|---|---|
| Day | |
| 2003-11-01 | 103536 |
| 2003-11-02 | 92051 |
| 2003-11-03 | 100795 |
| 2003-11-04 | 102352 |
| 2003-11-05 | 106569 |
Por defecto, Pandas crea un DatetimeIndex cuyo tipo es Timestamp, equivalente a np.datetime64, representando una serie temporal como una secuencia de medidas tomadas en un determinado momento. Un PeriodIndex, por otro lado, representa una serie temporal como una secuencia de cuantiles acumulados en periodos de tiempo. Los periodos suelen ser más fáciles de trabajar con ellos.
Variable de pasos de tiempo
Siempre que a la serie temporal no le falten fechas, podemos crear una time dummy contando la longitud de las series.
df = tunnel.copy()
df["Time"] = np.arange(len(tunnel.index))
df.head()| NumVehicles | Time | |
|---|---|---|
| Day | ||
| 2003-11-01 | 103536 | 0 |
| 2003-11-02 | 92051 | 1 |
| 2003-11-03 | 100795 | 2 |
| 2003-11-04 | 102352 | 3 |
| 2003-11-05 | 106569 | 4 |
Vamos a entrenar un modelo de regresión lineal.
from sklearn.linear_model import LinearRegression
X = df.loc[:, ["Time"]]
y = df.loc[:, "NumVehicles"]
model = LinearRegression()
model.fit(X, y)
# Almacena las predicciones como una serie temporal con el mismo
# índice de tiempo que los datos de entrenamiento
y_pred = pd.Series(model.predict(X), index=X.index)y_predDay
2003-11-01 98176.206344
2003-11-02 98198.703794
2003-11-03 98221.201243
2003-11-04 98243.698693
2003-11-05 98266.196142
...
2005-11-12 114869.313898
2005-11-13 114891.811347
2005-11-14 114914.308797
2005-11-15 114936.806247
2005-11-16 114959.303696
Length: 747, dtype: float64
Veamos cuáles son los coeficientes e intercept obtenidos:
model.coef_, model.intercept_(array([22.49744953]), 98176.20634409295)
Por tanto, el modelo creado realmente es, aproximadamente: Vehicles = 22.5 * Time + 98176. Al dibujar los valores obtenidos a lo largo del tiempo se muestra cómo la regresión lineal ajustada a la time dummy crea la línea de tendencia para esta ecuación.
# Establece valores por defecto de Matplotlib
plt.style.use("seaborn-whitegrid")
plt.rc("figure", autolayout=True, figsize=(11, 4))
plt.rc(
"axes",
labelweight="bold",
labelsize="large",
titleweight="bold",
titlesize=14,
titlepad=10,
)
plot_params = dict(
color="0.75",
style=".-",
markeredgecolor="0.25",
markerfacecolor="0.25",
legend=False,
)
ax = y.plot(**plot_params)
ax = y_pred.plot(ax=ax, linewidth=3)
ax.set_title('Time Plot del Tráfico del Túnel');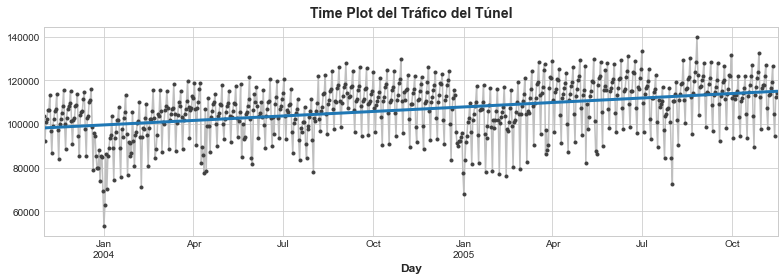
Variable lag
Pandas proporciona un método simple para “lagear” una serie, el método shift.
df["Lag_1"] = df["NumVehicles"].shift(1)
df.head()| NumVehicles | Time | Lag_1 | |
|---|---|---|---|
| Day | |||
| 2003-11-01 | 103536 | 0 | NaN |
| 2003-11-02 | 92051 | 1 | 103536.0 |
| 2003-11-03 | 100795 | 2 | 92051.0 |
| 2003-11-04 | 102352 | 3 | 100795.0 |
| 2003-11-05 | 106569 | 4 | 102352.0 |
Cuando creamos variables lag, necesitamos decidir qué hacer con los valores faltantes que se generan. Una opción es rellenarlos, quizas con 0.0 o con el primer valor conocido. En lugar de esto vamos a eliminar los valores faltantes, asegurándonos también de eliminar los valores del objetivo en las fechas correspondientes.
from sklearn.linear_model import LinearRegression
X = df.loc[:, ["Lag_1"]]
X.dropna(inplace=True)
y = df.loc[:, "NumVehicles"]
y, X = y.align(X, join="inner")
model = LinearRegression()
model.fit(X, y)
y_pred = pd.Series(model.predict(X), index=X.index)El diagrama de lag nos muestra cómo de bien somos capaces de ajustar la relación entre el número de vehículos de un día y el número del día anterior.
fig, ax = plt.subplots()
ax.plot(X['Lag_1'], y, '.', color='0.25')
ax.plot(X['Lag_1'], y_pred)
ax.set_aspect('equal')
ax.set_ylabel('NumVehicles')
ax.set_xlabel('Lag_1')
ax.set_title('Diagrama de lag del Tráfico del Túnel');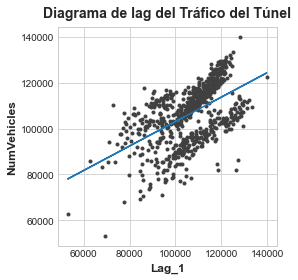
¿Qué significa esta predicción de la variable lag sobre cómo de bien puede predecir las series a lo largo del tiempo? El siguiente gráfico temporal nos muestra cómo nuestros pronósticos de ahora responden al comportamiento de las series del pasado reciente.
ax = y.plot(**plot_params)
ax = y_pred.plot()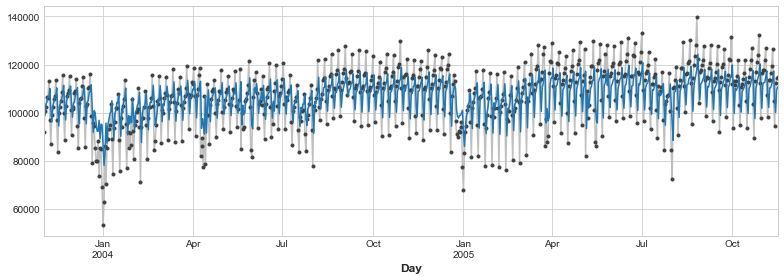
Los mejores modelos de series temporales normalmente incluirán alguna combinación entre variables de paso de tiempo y variables lag.
Ejercicio
Vamos a realizar un ejercicio para ampliar lo que acabamos de ver. Para ello cargaremos algunos datasets.
book_sales = pd.read_csv(
"../data/ventas.csv",
index_col="Date",
parse_dates=["Date"],
).drop("Paperback", axis=1)
book_sales["Time"] = np.arange(len(book_sales.index))
book_sales["Lag_1"] = book_sales["Ventas"].shift(1)
book_sales = book_sales.reindex(columns=["Ventas", "Time", "Lag_1"])
book_sales.head()| Ventas | Time | Lag_1 | |
|---|---|---|---|
| Date | |||
| 2000-04-01 | 139 | 0 | NaN |
| 2000-04-02 | 128 | 1 | 139.0 |
| 2000-04-03 | 172 | 2 | 128.0 |
| 2000-04-04 | 139 | 3 | 172.0 |
| 2000-04-05 | 191 | 4 | 139.0 |
Una de las ventajas que tiene la regresión lineal sobre algoritmos más complicados es que los modelos que genera son interpretables, es decir, es fácil interpretar la contribución que hace cada feature a las predicciones. En el modelo objetivo = peso * feature + bias, el peso nos dice cuánto cambia el objetivo de media por cada unidad de cambio de la feature.
Vamos a ver la regresión lineal de las ventas de libros:
fig, ax = plt.subplots()
ax.plot('Time', 'Ventas', data=book_sales, color='0.75')
ax = sns.regplot(x='Time', y='Ventas', data=book_sales, ci=None, scatter_kws=dict(color='0.25'))
ax.set_title('Gráfico temporal de venta de libros');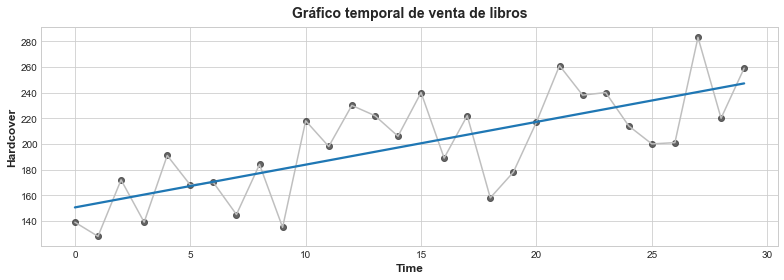
Interpretar la regresión lineal con time dummy
Digamos que la regresión lineal tiene una ecuación aproximada de: Ventas = 3.33 * Time + 150.5. Al cabo de 6 días, ¿cuánto se esperaría que cambiaran las ventas de libros?
Si aplicamos la fórmula, entonces 3.33 * 6 + 150.5 = 19.98. Luego se esperaría que las ventas sean de 19.98 libros. De acuerdo a este modelo, dado que la pendiente es 3.33, la venta de libros Ventas cambiará de media 3.33 unidades por cada paso que cambie Time.
Interpretar la regresión lineal con una variable lag
Interpretar los coeficientes de regresión puede ayudarnos a reconocer dependencias seriales en un gráfico temporal. Consideremos el modelo objetivo = peso * lag_1 + error, donde error es ruido aleatorio y peso es un número entre -1 y 1. En este caso, el peso nos dice cómo es de probable que el siguiente paso de tiempo tenga el mismo signo que el paso de tiempo anterior: un peso cercano a 1 significa que el objetivo probablemente tendrá el mismo signo que el paso previo, mientras que un peso cercano a -1 significa que el objetivo probablemente tendrá el signo opuesto.
Tenemos las siguientes dos series temporales:
ar = pd.read_csv("../data/ar.csv")
ar.head()| ar1 | ar2 | |
|---|---|---|
| 0 | 0.541286 | -1.234475 |
| 1 | -1.692950 | 3.532498 |
| 2 | -1.730106 | -3.915508 |
| 3 | -0.783524 | 2.820841 |
| 4 | -1.796207 | -1.084120 |
fig, (ax1, ax2) = plt.subplots(2, 1, figsize=(11, 5.5), sharex=True)
ax1.plot(ar['ar1'])
ax1.set_title('Series 1')
ax2.plot(ar['ar2'])
ax2.set_title('Series 2');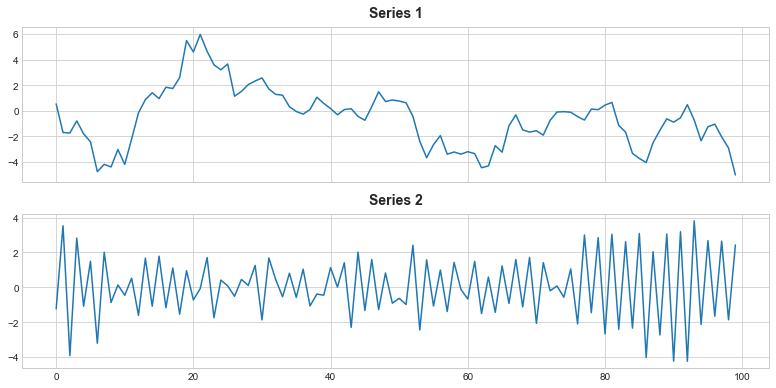
Una de estas series tiene la ecuación: objetivo = 0.95 * lag_1 + error y la otra tiene la ecuación objetivo = -0.95 * lag_1 + error, diferenciándose únicamente por el signo de la variable lag. ¿Qué ecuación correspondería a cada serie?
La Serie 1 estaría generada por la ecuación objetivo = 0.95 * lag_1 + error y la Serie 2 estaría generada por la ecuación objetivo = -0.95 * lag_1 + error. Como explicamos anteriormente, la serie con el peso 0.95 (signo positivo) tenderá a tener valores con signos que permanecen iguales. La serie con el peso -0.95 (signo negativo) tenderá a tener valores con signos que van y vienen.
Entrenar una variable de paso de tiempo
Vamos a cargar el dataset de la competición de Pronóstico de series temporales de ventas de almacén. El dataset completo contiene casi 1800 series registrando las ventas de una amplia variedad de familias de productos desde 2013 a 2017. En principio solo trabajaremos con una única serie (average_sales) de las ventas medias por día.
dtype = {
'store_nbr': 'category',
'family': 'category',
'sales': 'float32',
'onpromotion': 'uint64',
}
store_sales = pd.read_csv(
"../data/store_sales/train.csv",
dtype=dtype,
parse_dates=['date'],
infer_datetime_format=True,
)
store_sales.head()| id | date | store_nbr | family | sales | onpromotion | |
|---|---|---|---|---|---|---|
| 0 | 0 | 2013-01-01 | 1 | AUTOMOTIVE | 0.0 | 0 |
| 1 | 1 | 2013-01-01 | 1 | BABY CARE | 0.0 | 0 |
| 2 | 2 | 2013-01-01 | 1 | BEAUTY | 0.0 | 0 |
| 3 | 3 | 2013-01-01 | 1 | BEVERAGES | 0.0 | 0 |
| 4 | 4 | 2013-01-01 | 1 | BOOKS | 0.0 | 0 |
store_sales = store_sales.set_index('date').to_period('D')
store_sales = store_sales.set_index(['store_nbr', 'family'], append=True)
store_sales.head()| id | sales | onpromotion | |||
|---|---|---|---|---|---|
| date | store_nbr | family | |||
| 2013-01-01 | 1 | AUTOMOTIVE | 0 | 0.0 | 0 |
| BABY CARE | 1 | 0.0 | 0 | ||
| BEAUTY | 2 | 0.0 | 0 | ||
| BEVERAGES | 3 | 0.0 | 0 | ||
| BOOKS | 4 | 0.0 | 0 |
average_sales = store_sales.groupby('date').mean()['sales']
average_sales.head()date
2013-01-01 1.409438
2013-01-02 278.390808
2013-01-03 202.840195
2013-01-04 198.911148
2013-01-05 267.873230
Freq: D, Name: sales, dtype: float32
Vamos a crear un modelo de regresión lineal con una variable de paso de tiempo en la serie de promedio de ventas de producto. El objetivo es la columna sales.
from sklearn.linear_model import LinearRegression
df = average_sales.to_frame()
# Crea time dummy
time = np.arange(len(df.index))
df['time'] = time
# Crea los datos de entrenamiento
X = df.loc[:, ["time"]] # features
y = df.loc[:, "sales"] # objetivo
# Entrena el modelo
model = LinearRegression()
model.fit(X, y)
y_pred = pd.Series(model.predict(X), index=X.index)Vamos a dibujar la gráfica con el resultado:
ax = y.plot(**plot_params, alpha=0.5)
ax = y_pred.plot(ax=ax, linewidth=3)
ax.set_title('Gráfica temporal de Ventas totales');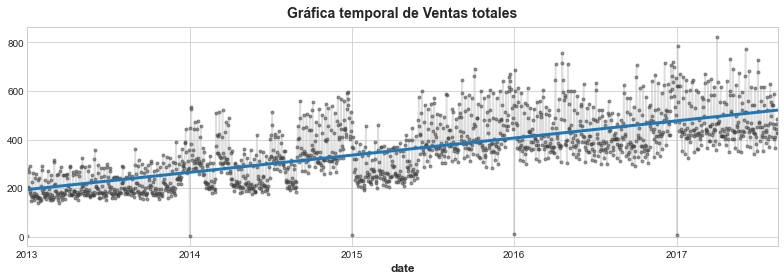
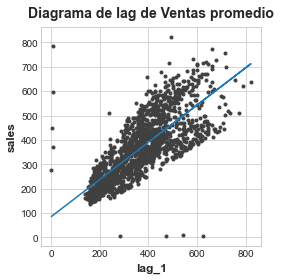
Entrenar una variable lag
Vamos a crear un modelo de regresión lineal con una variable lag en la serie de promedio de ventas de producto. El objetivo es la columna sales.
df = average_sales.to_frame()
# Crea la variable lag
lag_1 = df["sales"].shift(1)
df['lag_1'] = lag_1
X = df.loc[:, ['lag_1']].dropna() # features
y = df.loc[:, 'sales'] # target
y, X = y.align(X, join='inner')
model = LinearRegression()
model.fit(X,y)
y_pred = pd.Series(model.predict(X), index=X.index)Vamos a dibujar la gráfica con el resultado:
fig, ax = plt.subplots()
ax.plot(X['lag_1'], y, '.', color='0.25')
ax.plot(X['lag_1'], y_pred)
ax.set(aspect='equal', ylabel='sales', xlabel='lag_1', title='Diagrama de lag de Ventas promedio');